Kubernetes Operators are a key part of managing Kubernetes. They help you automate tasks such as provisioning, upgrading, and scaling your applications. In this blog post, we’ll show you how to use Ansible to prepare your Kubernetes Operator for deployment on OpenShift.
We’ll start by looking at the basics of operators. We’ll then show you how to handle custom resource default values. Finally, we’ll give you some tips on troubleshooting common issues with operators.
So, let’s get started!
What are Kubernetes operators?
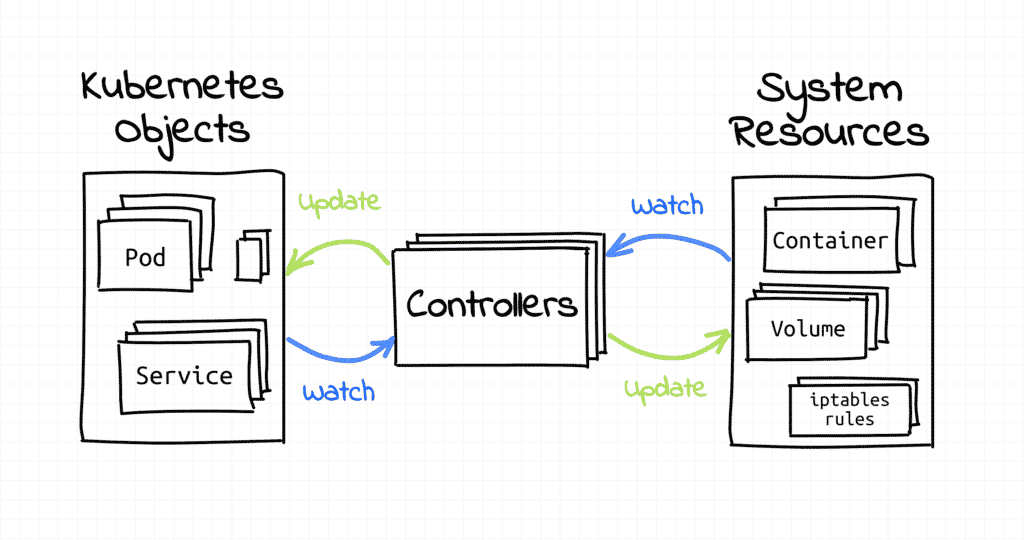
In simple terms, operators are programs that automate the management of specific types of workloads on Kubernetes.
For example, there are operators for managing databases, message queues, and monitoring solutions.
Operators typically extend the Kubernetes API to provide custom resources that represent the type of workload they manage. For example, a database operator would provide a CustomResourceDefinition(CRD) for database instances.
Operators use this CRD to create, update, and delete resources as needed to keep the cluster in sync with the desired state specified by the user.
For example, if you want to provision a new database, you would create a resource using the operator’s CRD. The operator would then use this resource to provision the database and keep it running.
Why use operators?
Operators have a number of advantages over traditional application management approaches.
First, they allow you to declaratively manage your applications. This means that you specify what state you want your application to be in, and the operator takes care of the rest.
For example, if you want to provision a new database, you would simply create a resource using the operator’s CRD. The operator would then take care of the rest, including provisioning the database and keeping it running.
Second, operators are much more portable than traditional application management approaches. This is because they are packaged as software that can be deployed on any Kubernetes cluster.
Third, operators can help you automate complex tasks such as provisioning, upgrading, and scaling your applications. This can save you a lot of time and effort compared to doing these tasks manually.
Finally, operators can make it easier to manage multiple instances of the same type of workload. For example, if you need to provision multiple databases, you can use a single operator to manage all of them. This is much easier than managing each database individually.
Installing operators
Operators can be installed either manually or using an Operator Lifecycle Manager (OLM).
Manual installation is the simplest way to install operators. However, it is only suitable for development and testing environments. This is because you need to manually deploy and manage the operator software on each Kubernetes cluster.
If you want to install operators in production environments, you should use an OLM. OLMs are designed to make it easy to deploy, update, and manage operators at scale.
The OperatorHub project provides a curated list of operators that can be installed using OLMs.
Custom resource default values | Ansible + Kubernetes Operators
The Ansible-based Operator SDK does not include a way to add handle custom resource default values out of the box. The trick I discovered requires you to make three changes to your Operator project.
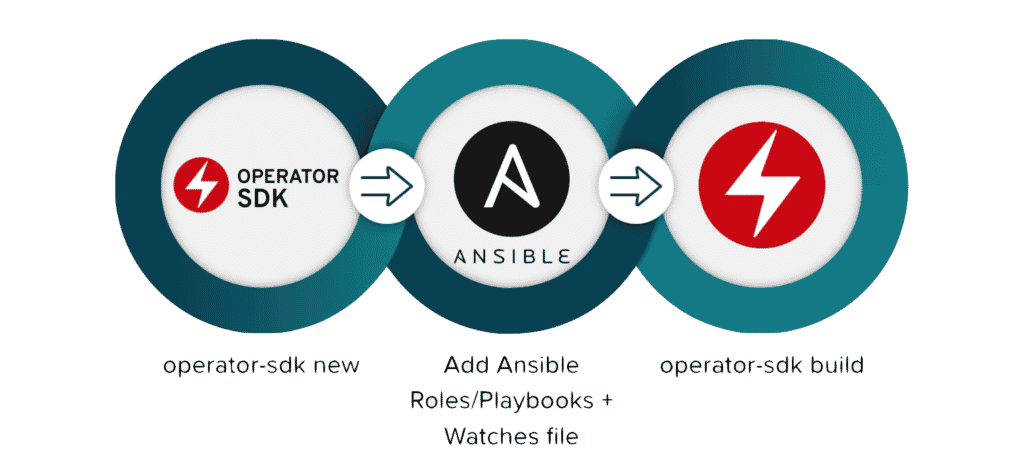
First, you need to install the Operator SDK on your workstation. You can find instructions for doing this in the Install the Operator SDK documentation.
Next, create a roles/fruitscatalog/default/main.yml file for handling default values. Be aware of Ansible’s usage of snake case, which is different from the camel case normally used for custom resource attributes.
Ansible, for example, converts replicaCount into replica count, so you must use this form in your Operator:
---
# defaults file for fruitscatalog
name: fruits-catalog-ansible
webapp:
replica_count: 1
image: quay.io/lbroudoux/fruits-catalog:latest
[...]
mongodb:
install: true
image: centos/mongodb-34-centos7:latest
persistent: true
volume_size: 2Gi
[...]The Operator SDK will use this file to initialize the missing parts in the user-supplied custom resource once it is present in your role. The SDK only supports a first-level merge, which is the approach’s limitation.
The other default child attributes will not be merged into the webapp variable if a user only enters webapp.replicaCount into the custom resource.
Essentially, you must handle the merge process explicitly, using Ansible’s combine() filter.
So, at the beginning of the role, we must ensure that we have a complete resource based on what the user provides and merged with default:
- name: Load default values from defaults/main.yml
include_vars:
file: ../defaults/main.yml
name: default_cr
- name: Complete Custom Resource spec with default values
set_fact:
webapp_full: "{{ default_cr.webapp|combine(webapp, recursive=True) }}"
mongodb_full: "{{ default_cr.mongodb|combine(mongodb, recursive=True) }}"The trick here is that the SDK-initialized webapp and mongodb variables cannot be written; instead, you must create new variables such as webapp_full and base your Ansible template on this later one. What’s nice about this approach is that it works perfectly when you run your Kubernetes Operator locally with make run or ansible-operator run.
Kubernetes Operator
Preparing your Kubernetes Operator for OpenShift with Ansible
If you’re looking to get your Kubernetes Operator up and running on OpenShift, there’s no need to reinvent the wheel. Ansible can help you get the job done quickly and easily.
The first thing you’ll need to do is install the Ansible Operator SDK. This can be done using pip:
pip install ansible-operatorOnce the SDK is installed, you’ll need to create a new file called “main.yml” in your project’s root directory. This file will contain the Ansible playbooks that will be used to provision and configure your Operator.
Next, you’ll need to define some variables that will be used by the playbooks. The most important variable is “k8s_api_version“. This variable tells Ansible which version of the Kubernetes API to use when interacting with your Operator. You can find this information by running “kubectl version“:
kubectl version
export k8s_api_version=v1.15.0With the “k8s_api_version” variable defined, you can now begin writing your playbooks. The first playbook, “install-deps.yml“, should be used to install any dependencies that are required by your Operator. For example, if your Operator needs to interact with the Kubernetes API, you’ll need to install the Python “kubernetes” module:
- name: Install dependencies
hosts: localhost
connection: local
tasks:
- name: Install Python kubernetes module
pip:
name: kubernetesThe next playbook, “configure-operator.yml“, should be used to configure your Operator for deployment on OpenShift. There are a few things you’ll need to do in this playbook. First, you’ll need to set the “namespace” and “service_account_name” variables. These variables tell Ansible which namespace and service account to use when deploying your Operator.
Next, you’ll need to create a new file called “kustomization.yaml“. This file will be used by Kubernetes to customize the deployment of your Operator. In this file, you’ll need to set the “apiVersion” and “kind” fields to match the values of the “k8s_api_version” and “operator_kind” variables, respectively. You’ll also need to set the “namespace” field to the value of the “namespace” variable. Here’s an example kustomization.yaml file:
apiVersion: {{ k8s_api_version }}
kind: {{ operator_kind }}
namespace: {{ namespace }}Once you’ve created the “kustomization.yaml” file, you can deploy your Operator using the “oc” command:
oc apply -kAnd that’s it! You should now have a fully functioning Kubernetes Operator up and running on OpenShift.
Tips on troubleshooting common issues with operators
Kubernetes operators are a great way to manage your containerized workloads, but they can sometimes be a bit finicky. If you’re having trouble with your operators, here are a few tips to help you troubleshoot the most common issues:
- Make sure your operator manifests are valid and up-to-date. Invalid manifests are one of the most common causes of operator issues.
- Check the Kubernetes event logs for clues about what might be going wrong. The event logs can be a goldmine of information when it comes to troubleshooting Kubernetes issues.
- Use the kubectl describe and kubectl get commands to gather information about your operators and resources. This information can be very helpful in pinpointing the cause of an issue.
Ask for help! There’s a vibrant community of Kubernetes users and developers who are always happy to help out with operator issues. If you’re stuck, don’t hesitate to reach out for assistance.


