As developers, we are always looking for ways to enhance everything from how people communicate to how they buy goods. The purpose, undoubtedly, is to increase human productivity.
The software development landscape has seen a tremendous growth in the adoption of developer productivity tools in order to boost human productivity.
This is especially true in the software infrastructure industry. Innovative methods are being developed that allow developers to focus on writing actual business logic rather than tedious deployment difficulties.
The aim to improve developer experience and minimise expenses are two of the key drivers of serverless computing. But, exactly, what is serverless computing? That is the crux, the ‘meat and potatoes’ of this guide.

Let’s get this party started, shall we?
What exactly is Serverless?
To grasp serverless computing, we must first comprehend what servers are and how they have evolved through time.
Making an application discoverable includes uploading it to a specific computer that operates continuously and at high speeds. A server is a computer of this sort.
A brief history lesson on the evolution of servers
A company wants to transfer a piece of software they created to a server.

Two decades ago – They would have to buy a physical computer, configure it, and then deploy their program to it.
They’d have to acquire and set up additional servers if they needed to upload multiple programs. Everything was completed on-site, or on-prem.
However, it didn’t take long for people to identify the numerous issues that occurred with approaching servers in this manner.
Problem: developer productivity

The attention of a developer is divided between developing code and dealing with the infrastructure that supports the code. This problem might simply be solved by delegating infrastructure maintenance to others—this leads to a second problem.
The second problem: cost

These individuals dealing with infrastructure issues would have to be compensated, right? In reality, even for relatively simple test applications, purchasing a server is an expensive investment.
And this is before we consider other factors such as expanding a server’s computing capability during a spike in traffic or just updating the server’s OS and drivers over time…well, you can see how exhausting it is to maintain an in-house server.
Amazon Acts
Amazon reacted to this demand in 2006, when it announced the launch of Amazon Web Services (AWS). AWS is well-known for causing havoc in the software infrastructure industry. It was a radical departure from “traditional” servers.

AWS eliminated the need for businesses to build up their own servers. This was massive.
Instead, businesses and people could simply upload their applications to Amazon’s computers via the internet for a fee. And the server-as-a-service concept signalled the beginning of cloud computing era.
Back to the question: What exactly is cloud computing?
In simple terms – Cloud computing is the supply of computer services such as servers, storage, databases, networking, software, analytics, and intelligence—over the Internet (“the cloud”) to provide speedier innovation, flexible resources, and economies of scale.

What makes cloud computing so remarkable is that you can be in Madagascar and rent a computer in the United States.
In cloud computing terminology, cloud computing models relate to the many environments or services that most cloud vendors provide. Each new model in the cloud computing industry is often designed to increase developer productivity while decreasing infrastructure and personnel expenses.
Types of cloud services?
Let us now examine the three major categories of cloud services.

Software as a Service (SaaS) – Software as a Service provides a variety of services such as file storage, backup, web-based email, and project management tools.
Users can access, store, share, and safeguard information on the cloud by using one of these applications.
Example: Dropbox, MailChimp, Slack.
Platform as a Service (PaaS) – Platform as a service is a cloud environment where developers may build and deploy applications.
PaaS provides the database and operating system required for the development of cloud-based software. Developers can concentrate on their work without having to design and maintain the infrastructure that is often required for software development processes.
Example: OpenShift, Elastic Beanstalk, Heroku.
Infrastructure as a Service (IaaS) – IaaS provides the infrastructure required to manage SaaS tools, such as servers, storage, and networking resources.
The storage servers and networking infrastructure would be managed by the cloud provider, who may also provide additional services such as load balancing and firewalls.
Example: Google Compute Engine, Amazon Web Services, Microsoft Azure, Linode.
The Ascension of Serverless Computing

Serverless computing, like IaaS and PaaS, is a cloud computing model. It is the most recent cloud advancement, following PaaS. Serverless, like IaaS and PaaS, does not require the purchase of real computers.
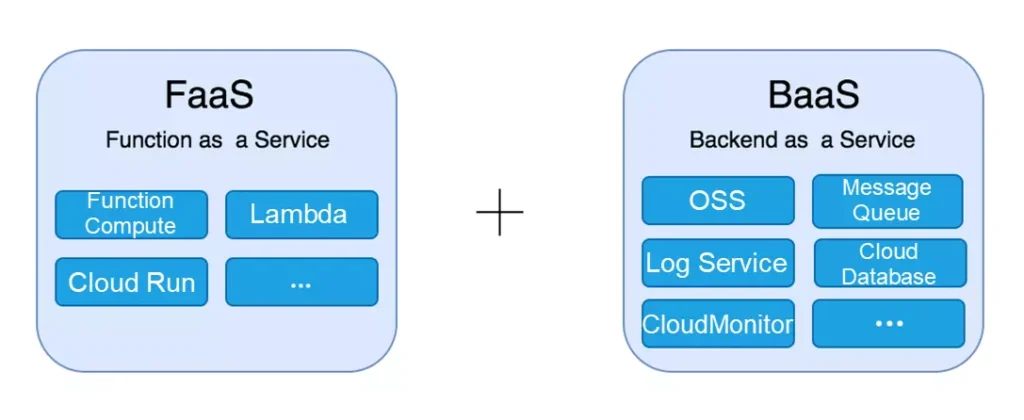
Backend as a Service(BaaS) vs. Function as a Service(FaaS)

Every serverless solution falls into one of two categories:
Function as a Service (FaaS) – A cloud solution is termed FaaS, and hence serverless, if it eliminates the requirement for us to install our applications as single instances that are then operated as processes within a host.
Backend as a Service (BaaS) – A cloud solution is regarded a BaaS, and hence serverless, if it substitutes components of our application that we would normally build or manage ourselves.

When you utilise Google’s Firebase authentication service or Amazon’s Cognito service to manage user authentication in your project, you’ve taken advantage of a BaaS offering.
In summary – FaaS and BaaS
- For apps that we deploy, we do not need to manage long-lived application instances or hosts.
- We don’t have to manually scale up or down computer resources based on traffic because the server does it for us.
- Pricing is determined solely by usage.
Any application that is based on a large number of BaaS solutions or designed to be deployed on a FaaS platform, or both, can be deemed serverless.
Now that we’ve covered the basics of serverless, let’s look at how we can create a simple deployment with AWS Lambda and Python
AWS Lambda and Python | Very Easy Guide

STEP 1: Installing required packages locally
1. Install serverless
npm install -g serverless2. Create a repo for aws-lambda
serverless create --template aws-python3 \ --name test_project --path test_project3. Create your virtualenv and activate it. (This is to keep requirements isolated in python)
virtualenv env --python=python3 & source env/bin/activate4. Install Docker (necessary to set up native packages on AWS lambda)
STEP 2: Set up AWS
You must have an access id, access key, and params in order to push to AWS Lambda via the command line.
1. Create an AWS Account (if you haven’t already)
2. Create a new access key, or find ones you’ve already made before. Keys can be accessed here. https://console.aws.amazon.com/iam/home?#/security_credentials

3. Store the access key id and access key on your local environment. (Required for serverless)
export AWS_ACCESS_KEY_ID=<YOUR_KEY_ID> AWS_SECRET_ACCESS_KEY <YOUR SECRET_ID>STEP 3: Update Python code on your machine
Remember how you ran create serverless, now enter into the directory cd test_project. There are two files of importance handler.py and serverless.yml
handler.py is where your python code lives. Update it appropriately.
# handler.py
# Following code is needed if you have to zip requirements. This happens when your package is too big
# try:
# import unzip_requirements
# except ImportError:
# pass
def main(event, context):
print("hello world")
# More Sample code
if __name__ == "__main__":
main('', '')To run on your own machine
python handler.pyserverless.yml is where you configure serverless for uploading.
# name your project
service: test-project
provider:
name: aws
runtime: python3.10
# install python
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: non-linux
# zip: true Only set this to true if AWS rejects your uploads
functions:
sample-scraper:
handler: handler.main
timeout: 30 # 30 second time out (default is 6)
events:
- schedule: cron(5 19 * * ? *) # Runs daily at PST 12:00pmFINAL STEP: Deploy and debug
1. Run the deployment script, it will take a few minutes.
serverless deployWhen it’s finished, make sure AWS lambda is properly updated.
2. Use your command line to invoke and call the function.
serverless invoke -f sample-scraper --logA few final Tips
- Update the cron field in the serverless.yml file to change the frequency.
- Zip the requirements if the file size is too large. In serverless.yml, change zip:true.
- To save a file locally – Lambda supports writing to the /tmp directory. Once there, you can utilise s3 to offload to another location.


